Damit qualitativ Forschende sich zusammenfinden und zwar nicht mühsam, hat Oliver Zetsche aus Leipzig das Netzwerkportal Qualitative Sozialforschung gegründet. Hier erhält der geneigte Forschende einen Überblick über gängige Methoden, Veranstaltungen und Call for Papers, kann sich mit anderen Leidensgenoss*innen vernetzen und ein Forum zum diskutieren nutzen. Als Leipziger wünschen wir dem Oliver natürlich gutes Gelingen. Vielleicht kooperieren wir eines Tages und reißen gemeinsam die qsf-Weltherrschaft an uns und holen sie nach Leipzig. Ha!
Author: sosciso
Categories
New + Case Study: NVivotools
Author: Jonathan Schultz, (BarraQDA.org)
Summary
NVivotools provides a way to interface NVivo with other software tools. It can be used at each stage of the QDA process – data entry, coding, analysis, reporting and archiving. This blog post outlines how it works and its potential applications. It then describes the author’s experience of using it in a simple real-world example.
Introduction
NVivo is probably the most widely used software for QDA. It provides an integrated GUI-driven system for managing, coding and reporting on research material in textual, audio and video form. Yet it suffers from a number of shortcomings, some of which NVivotools seeks to overcome. Most notably:
1. NVivo uses a closed (proprietary) data format to ‘lock up’ your data and prevent you from using other software with it. By freeing your research data from this environment, NVivotools lets you use the wide range of free and non-free tools for data harvesting, manipulation, coding, analysis, reporting and archiving.
2. NVivo requires a fairly powerful Windows or Mac computer. There is no chance of coding on a portable device or Linux box, and even your old Windows computer will struggle with any but the smallest research project. By using the simple and lightweight SQLite database and allowing you to use your own tools, NVivotools makes computer assisted QDA accessible on smaller and cheaper devices, including Linux machines.
3. NVivo’s GUI is great for users who are starting out and need help finding their way around, but for everyone else it quickly becomes a handicap. It makes small errors almost inevitable and provides no means of validation as it leaves no record of the steps that have been taken, and it cannot be automated. NVivotools provides another way to work on your research data using powerful scripting languages such as R and Python.
How it works
NVivotools accesses NVivo files (which are actually database files – Microsoft SQL Server for the Windows edition and SQL Anywhere for the Mac edition). It provides command-line tools to transform NVivo data from an NVivo file into and out a simpler and more easily accessed database, which it refers to as the normalised database. Because NVivotools uses the Python module SQLAlchemy for database access, it is able to deploy many different database engines for the normalised database. By far the simplest of these is SQLite, and NVivotools largely assumes that this is the one you will use.
The normalised database format is (almost) self-explanatory. Files can be opened with any program that can read SQLite files (try SQLiteBrowser as a first point of call) and the structure and content of the NVivo project data extracted, modified, added to or otherwise used at will. The data can also be re-imported into an NVivo project file, making any changes available within NVivo. In this way, researchers can tailor the data analysis to suit a particular project, and write or make use of existing tools to work with the data.
To use NVivotools, you can either install it on your own computer, or use an online version. In either case, it is free to use or redistribute, subject to the usual GPL licence conditions.
A simple example
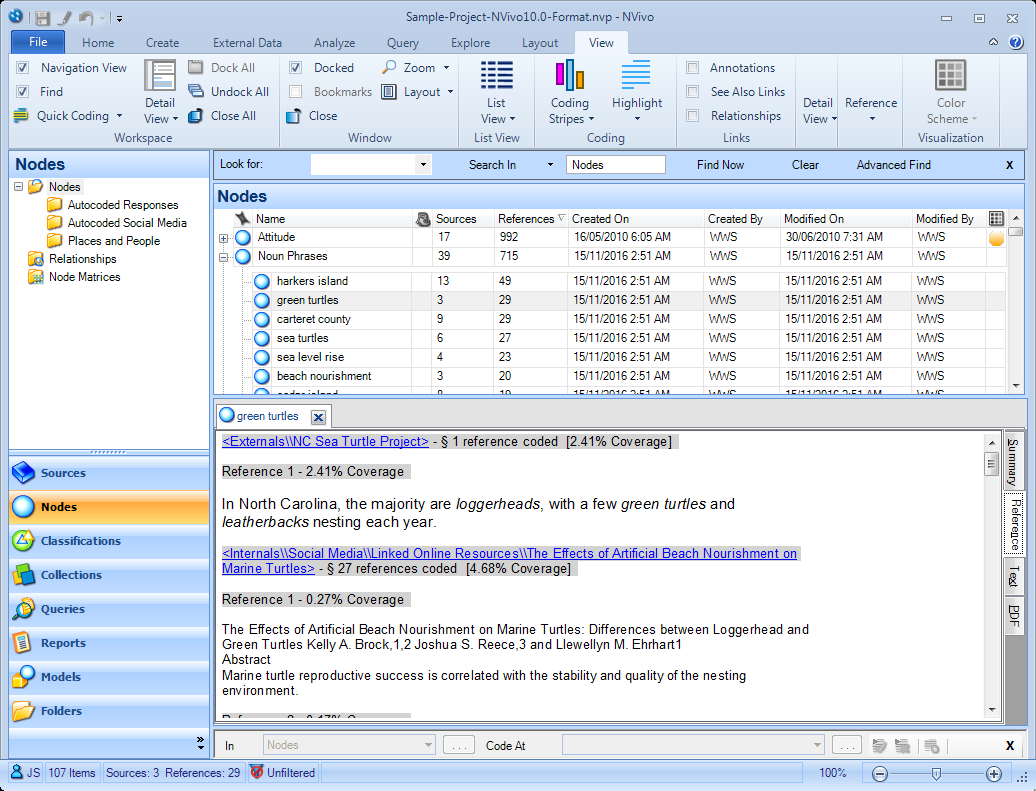
As a demonstration of NVivo’s potential, the author took NVivo’s sample project for NVivo 10 for Windows, which can be downloaded here. This demonstration script uses Python’s textblob module to find the most commonly occurring noun phrases across all the sources in the project. It creates a node for a lemmatised version of each noun phrase, and codes every sentence that contains one of them at that node. In order to limit the number of noun phrases, it allows the user to specify the minimum number of times the noun phrase must occur to be included.
Installing textblob requires two commands:
$ pip install textblob $ python -m textblob.download_corpora
To use NVivotools, first convert the sample project to a normalised database. This creates an output which by default has the same name as the input file, with the extension .nvp replaced by .norm:
C:> NormaliseNVP.py Sample-Project-NVivo10.0-Format.nvp Using MSSQL instance: QSRNVIVO10 File activation failure. The physical file name "C:\Users\jschultz\Documents\NVivo 10 Sample Project_log.LDF" may be incorrect. New log file 'C:\Users\jschultz\AppData\Local\Temp\SQL\tmpdx9ri9_log.LDF' was created. Msg 15025, Level 16, State 1, Server WINDOWS7-TS\QSRNVIVO10, Line 1 The server principal 'nvivotools' already exists. Attached database nt1456 Normalising users Normalising project Normalising node categories Normalising nodes Normalising node attributes Normalising source categories Normalising sources Normalising source attributes Normalising taggings Normalising annotations Dropped database nt1456
Next, run the demonstration script with the occurrence threshold set to 5. Notice that the database engine is specified explicitly here as SQLite. This command does the actual textual analysis and adds the nodes and coding information to the normalised file.
C:> textblobExampleCode.py --threshold 5 sqlite:///Sample-Project-NVivo10.0-Format.norm
The resulting data can then be reloaded into the original sample project file. If you try this with real live data, make sure you have a backup!
C:> DenormaliseNVP.py Sample-Project-NVivo10.0-Format.norm Sample-Project-NVivo10.0-Format.nvp Using MSSQL instance: QSRNVIVO10 File activation failure. The physical file name "C:\Development\NVivo\Development\Main\NVivo\Installer\Client\Databases\Sample Project_log.LDF" may be incorrect. New log file 'C:\Users\jschultz\AppData\Local\Temp\SQL\tmpwsr7o4_log.LDF' was created. Msg 15025, Level 16, State 1, Server WINDOWS7-TS\QSRNVIVO10, Line 1 The server principal 'nvivotools' already exists. Attached database nt3504 Denormalising users Denormalising project Denormalising node categories Denormalising nodes Denormalising node attributes Denormalising source categories Denormalising sources Denormalising source attributes Denormalising taggings and/or annotations WARNING: Unrecognised tagging fragment: 0:-2 for Source: NC Sea Turtle Project WARNING: Unrecognised tagging fragment: 0:-2 for Source: Barrier island undeveloped Saved database nt3504
Don’t worry about those warnings – they refer to more complex coding from the NVivo project that NVivotools currently ignores. Now open the modified NVivo project file, and you can see the nodes that have been created under the top-level node ‘Noun Phrases’. In the screenshot below, you can see that the node ‘green turtles’ has been opened, and two of the 29 selections containing the words ‘green turtles’ can be seen.
Conclusion
As this simple example demonstrates, NVivotools makes it easy to retrieve your data from NVivo, from where it can be examined and analysed, and if required imported back into NVivo. This gives researchers great scope to integrate NVivo more strongly with existing IT systems at each phase of a research project. As NVivotools is written in Python and has an Open Source (GPLv3) licence, it is and will remain free to use, as well as to examine, fork, modify and contribute to. There is certainly scope for improvement and to build it into a more integrated engine for computer assisted QDA using Open Standards. Nonetheless in its current state, it can be a useful addition to a CAQDAS toolkit.
Categories
Software for timelines
Vor kurzem standen wir vor der Aufgabe, den zeitlichen Ablauf unseres Forschungsprozesses (Daten der Interviews und Beobachtungen, Daten der durch unsere Proband*innen berichteten Ereignisse, Daten relevanter Kontextereignisse) in einer Übersicht zusammenzustellen. Man könnte das gewollte Ergebnis als Forschungsprojektzeitstrahl bezeichnen. Natürlich dachten wir uns, dafür muss es doch Software geben, die uns dabei helfen kann. Und siehe da, bei unserer Recherche sind wir auf einige sehr interessante Programme gestoßen, die wir an der Stelle gerne weiterreichen möchten.
Zu allererst der Hinweis auf den Lehrerfreund. Während einer kurzen Recherche sind wir auf die schöne Übersicht gestoßen und waren dann auch sehr froh darüber, nicht mehr weitersuchen zu müssen. Denn in der Übersicht sind ein paar sehr brauchbare Hinweise dabeigewesen.
Timeline
Unsere Empfehlung ist die Software Timeline. Timeline ist Open Source und läuft auf den gängigen Plattformen, solange man Python installiert bekommt. Zu Timeline gibt es auch einen sehr informativen Blog auf Deutsch: https://timelinedeutsch.wordpress.com. Das Programm ist recht intuitiv zu bedienen, sprich, wir brauchten nicht sonderlich lange, um uns an die Dateneingabe und die Konzepte in Timeline zu gewöhnen. Der Nachteil liegt hingegen in der Schlichtheit des Programmes, es bietet halt nicht sonderlich viel Optionen in Bezug auf Darstellung oder Dateneingabe. Für unsere Zwecke hat es hingegen völlig gereicht.

Chronozoom
Wer es abgefahren mag, der sollte sich mal Chronozoom anschauen, ein webbasiertes Werkzeug welches an Universitäten in Berkeley und Moskau sowie von Microsoft entwickelt wird. Der Zeitstrahl kann hier in Systeme unterteilt werden, die auch wiederum einen zeitlichen Verlauf aufzeigen. Schaut mal hier rein. Wie unwichtig doch die sich so wichtig nehmende Menschheit ist….
Liniaa
Ebenfalls interessant empfanden wir liniaa. Wir haben es zwar nicht getestet, aber die Darstellung dieses webbasierten Werkzeuges hat uns sehr überzeugt.
Andere Werkzeuge haben wir daraufhin gar nicht mehr getestet. Der kurze Ausflug in die Welt der Werkzeuge für die Zeitstrahlerstellung war sehr bereichernd. Und apropos Zeitstrahl: Wochenende!
Liebe Leser*innen, falls ihr schon immer mal wissen wolltet, was wir neben akademisieren und der Suche nach dem heiligen Gral der Werkzeuge für die Sozialwissenschaftler*in noch so machen, der darf gern auch mal hier: https://betacoop.de/ oder hier: http://kgb.bio vorbeischneien. Wer in Leipzig, Chemnitz oder Halle wohnen sollte, kann sich gern über den Korrekten Getränke Betrieb korrekte Getränke bestellen. Aktuell hat die Betacoop e.G. wieder eine Projektförderrunde für gemeinnützige Initiativen ausgeschrieben, deren Bewerbungsfrist mittlerweile vorbei ist – sorry für den späten Beitrag hier. Na dann, gute Nacht.
![]()
Categories
Literaturtip: Ragoût brusque
Heute eine kleine kurze Leseempfehlung vom LIBREAS.Library Ideas Blog. Eine kleine Replik auf einen fragwürdigen FAZ-Artikel zu Open Access.
Der heutige Blogeintrag kommt als Gemischtwarenladen daher. Wir präsentieren euch heute alle möglichen Sachen, die wir in den letzten Monaten nebenbei mit aufgesammelt haben.
750 Words
Alle, die sich beim Schreiben gerne ablenken lassen, sollten mal das Angebot auf der Webseite http://750words.com/ ausprobieren. Laut Webseite stehen die 750 Wörter für 3 Seiten assoziativem Schreibens. Jeden Morgen sollen so die Schreibblockaden gelöst werden. Wir können das sehr empfehlen. Assoziatives Schreiben hat uns aus mancher Schreibblockade gerettet.
How to formulate a good research question?
…das und andere forschungsprozessrelevante Fragen stellten sich die Autor*innen des ersten Moduls IFN001 für Promotionsstudierende der Queensland University of Technology. Selbstredend wird auch versucht, die Fragen zu beantworten. Wir finden die Übersicht durchaus gelungen und legen den angehenden Wissenschaftler*innen unter Euch die Lektüre sehr ans Herz.
Tips und Tricks und andere Hacks
Auf http://matt.might.net/articles/productivity-tips-hints-hacks-tricks-for-grad-students-academics/ gibt es Produktivitätstips für Akademiker*innen. Das Department of Anthropology an der Durham University hat sich dem Schreibprozess an sich gewidmet und unter https://www.dur.ac.uk/writingacrossboundaries/writingonwriting/ einige Wissenschaftler*innen nach ihren Geheimnissen befragt. Der oder die Thesis Whisperer hat wiederum usefull resources for students and supervisors zusammengetragen.